
# What could go wrong?
- Heteroskedasticity
- Multicollinearity
- Latent variables
# Using nonlinear features of the data
# Overfitting and regularization
# Performance assessment, testing and validation
- Selecting a model class and algo
- Training versus testing
- Cross-validation
- Bootstrap
# Heteroskedasticity
- Variance $\sigma_i^2$ of $W_i$ changes with i (maybe depend on $X_i$)
- If we knew $\sigma_i^2$, could use a weighted least squares criterion
- Heteroskedasticity frequently occurs when the size of the observations differ much
- Formulas for SE etc. don't hold
# Multicollinearity
- Vector X (approximately) confined to a lower-dimension set
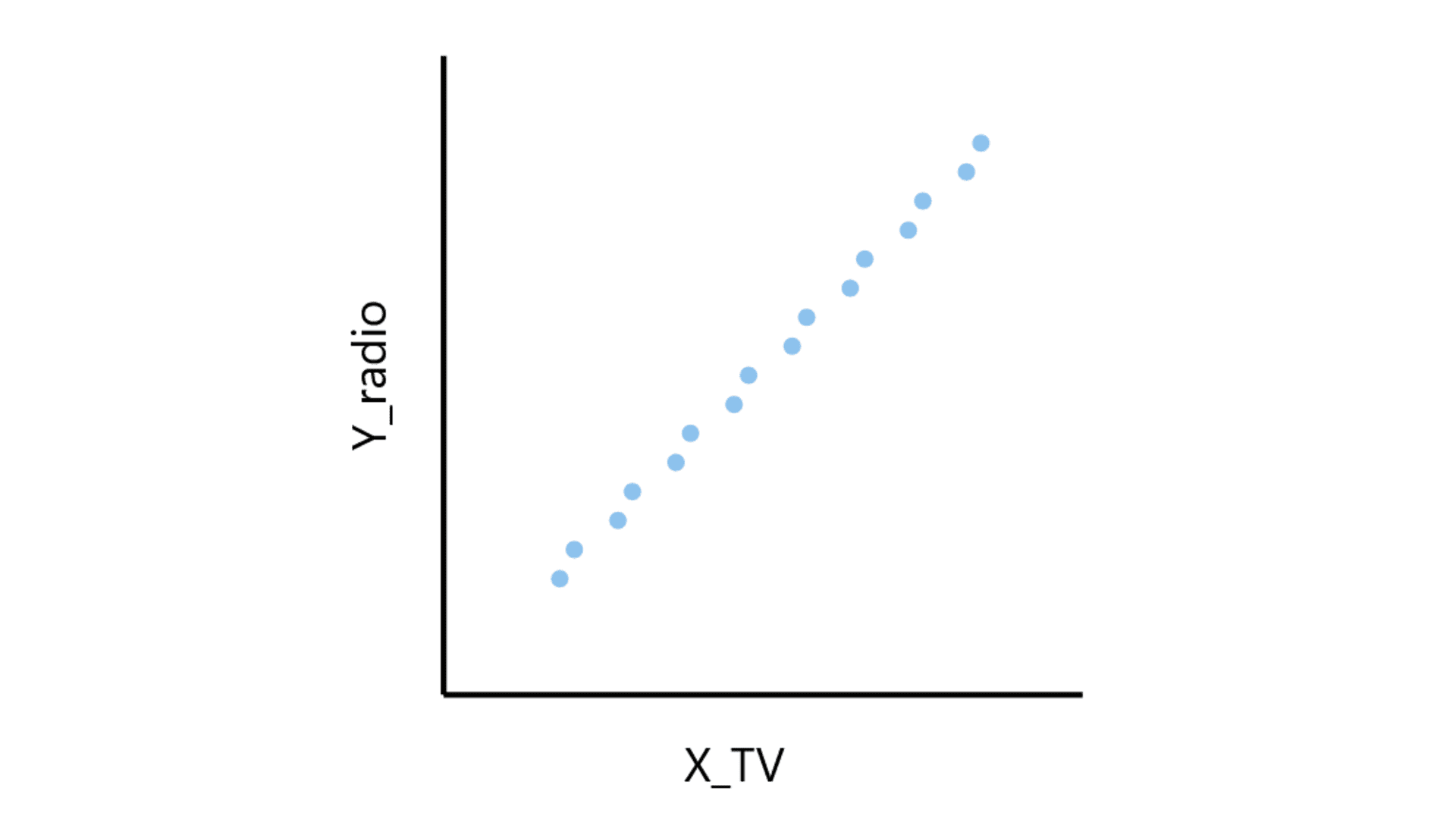
Notes about the graph:
- As TV ads grows, Radio ads also grows. So they are well aligned
- We don't know relative effect of TV ads vs radio ads
- Sale keeps increasing but we don't know who to attribute to - higher TV ads or higher radio ads
- SE infinite or huge
- We just remove redundant var, or reduce them
- Modeling is different than prediction
[Key points for linear regression:]
- The variables should be measured at continuous level
- There should be a linear relationship between the variables
- There should be no significant outliers in the given data
Connection between eating more chocolate and winning the nobel prize.
Data may useful for making predictions. They don't have enough info for drawing conclusions about causality or structure model.
Comments NOTHING